The tormenting of the body by the troubled mind, hysteria was among the most pervasive of human disorders in the 19th century – yet at the same time, the most elusive. Studies in Hysteria (1895) describes the birthplace of Psychoanalysis; two doctors trying to understand the causes of this debilitating condition. Freud’s recognition that hysteria stemmed from traumas in the patient’s past transformed how we think about the mind and sexuality. This book is one of the founding texts of psychoanalysis, revolutionizing our understanding of love, desire and the human psyche.
In the following summary notes, I have extracted highlights, key quotes, and observations in the hope that they would inspire others to begin their reading journey on the great classics of Psychology.
There are many translations of this book. However, I found the Penguin Modern Classics version to be most adequate.
The Book in 3 Quotes
1. For we found, at first to our great surprise, that the individual hysterical symptoms disappeared immediately and did not recur if we succeeded in wakening the memory of the precipitating event with complete clarity, arousing with it the accompanying affect, and if the patient then depicted the event in the greatest possible detail and put words to the affect.
2. Words are far from being just a Neutral tool for stating a fact or communicating a message. Like weapons, they may hit and hurt (and it is by the same logic that they can also heal).
3. In a chain of associations ambiguous words act like points at a junction. Along the second track run the thoughts we are in search of.
I: On the Psychical Mechanism of Hysterical Phenomena
In this section, Freud and Breuer explore what exactly is the cause of hysteria. By their estimation, it results from traumatic experiences which have not been dealt with appropriately and often have been completely forgotten. Yet are alive and well in an individual’s unconscious.
1
Quote from the chapter: “Our experiences have, however, shown that the most diverse symptoms which are held to be spontaneous, so to speak idiopathic products of hysteria, maintain an equally compelling connection to there precipitating trauma as do those phenomena mentioned above where the connection is quite transparent.”
Contents: Part 1 of the chapter introduces the findings this book intends to report on. Showing how hysteria can emerge from seemingly unrelated and often forgotten events in a person’s life. It is revealed that by talking, processing, and reliving the experience, a person can overcome its negative effects.
What is Hysteria? A psychological disorder characterised by the conversion of psychological stress into physical symptoms (somatization) or a change in self-awareness (such as a fugue state or selective amnesia). Today, hysteria is no longer a recognised illness, but different manifestations of hysteria are observed in present-day conditions such as schizophrenia, borderline personality disorder, conversion disorder and anxiety attacks.
My Observations: Relating to the quote: “For we found, at first to our great surprise, that the individual hysterical symptoms disappeared immediately and did not recur if we succeeded in wakening the memory of the precipitating event with complete clarity, arousing with it the accompanying affect, and if the patient then depicted the event in the greatest possible detail and put words to the affect.” James Pennebaker’s work on expressive writing touches on this phenomenon. Through written reflection, you may realize that a certain unpleasant feeling ties back to, for example, a difficult interaction with a family member. Research has shown that such insight can help locate, ground and ultimately resolve the emotion and its associated stress.
2
Quote from the chapter: “Whether a memory fades or rids itself of affect depends on several factors. Of the greatest importance is whether or not there was an energetic reaction to the affecting event. By reaction we mean here the whole set of voluntary and involuntary reflexes – from tears to acts of revenge – into which, as experience shows, emotions are discharged. If this reaction ensues to a sufficient extent, a large part of the affect will disappear; our language testifies to this fact of daily observation with expressions such as ‘to let off steam’, ‘to cry one’s eyes out’ and so on. If the reaction is suppressed the affect remains bound up with the memory. An insult which has been repaid, albeit only verbally, will be remembered differently from one that had to be accepted.”
Contents: Here, we are introduced to the concepts of Catharsis and Abreaction.
Catharsis being the lively remembering of a traumatic experience in addition to an emotional release; ‘to let off steam’ ‘to cry one’s eyes out’ and so on. If the reaction is suppressed, the effect remains bound up with the memory. The hurt person’s reaction to trauma only has a “cathartic” effect if it is an adequate reaction.
An Abreaction is a surrogate action which someone can take to help rid themselves of a traumatic memory in a cathartic manner. For example, talking, complaining or confessing a secret are all abreactions to a particular circumstance. Both allow the traumatic memory to be dealt with.
Finally, not everything needs to be reacted or abreacted. Sometimes things happen after the event which have a cathartic effect through association. For example, the rescue which follows the danger, or the apology which follows a hurtful statement. It is neither reaction nor abreaction, but rather association.
Memories are sometimes not reacted to correctly for two main reasons. Firstly, when the nature of the trauma prevents reaction (for example, the social circumstances cause the person to suppress the reaction). Secondly, when the nature of the person prevents reaction (for example, they are stricken with fear, intoxicated, or distracted). These two reasons will often occur at the same time.
My Observations: Another cathartic abreaction might be to write down the event in great detail and see what learnings you can take from it. Our memory serves to help us learn, and rumination on a traumatic memory will often happen if we have not learnt the lesson within the experience.
3
Quote from the chapter: “The more we were occupied with these phenomena the more convinced we became that the splitting of consciousness that is so strikingly present in the well-known cases as double conscience, exists in a rudimentary form in every hysteria; and that this tendency to dissociation and thereby to the emergence of abnormal states of consciousness, which we will group together under the term ‘hypnoid’, is the fundamental phenomenon of this neurosis.”
“We would then set a proposition alongside the often sited, ‘Hypnosis is artificial hysteria’, namely that the basis and condition of hysteria is the existence of hypnoid states.”
Contents: Here, Freud introduces hypnoid states; altered states of consciousness that emerge from dissociation or a splitting of consciousness. A daydream is an example of a hypnoid state, which Freud believed showed that an individual might be more or less predisposed to enter into this state more than others. Another key element that comes up in this chapter is that these traumatic experiences are inaccessible without hypnosis.
My Observations: In a Journal article from 1910 on the Treatment of Insanity (15 years after Studies in Hysteria was written), Morton Prince writes: “Hypnosis is only necessary in a minority of cases where it is considered that suggestibility should be increased.” By this time, the interest in hysteria had already decreased significantly (see graph below).
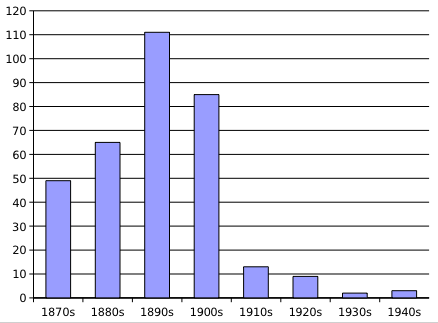
This book documents the birthplace of a lot of Freud’s thoughts and ideas. The best concepts have been carried forward into modernity and others (such as the understanding of what hysteria was and the need for hypnosis) being discarded. Morton then states:
“The process by which certain of these syndromes are created is educational. Hence it should be possible by educational methods to disintegrate complexes which have become harmful to the personality.”
Further than abreaction and reaction, education and understanding also play an important role in catharsis. As notably said by Carl Jung, “Until you make the unconscious conscious it will guide your actions and you will call it fate”.
Additional notes: The causative notion of hypnoid states was later repudiated by Freud in favour of his theory of repression. Hypnosis has also remained in use in varying capacities over the years, with the body of evidence supporting its efficacy growing significantly.
4
Quote from the chapter: “We can arrive at a particular appreciation of the hysterical attack by taking into account the theory (indicated above) that in hysteria groups of ideas originating in hypnoid states are present which are excluded from associative exchange with the other ideas, but which, as they can associate amongst themselves, represent the more or less highly organized rudiment of a second consciousness, a condition seconde. A long-term hysterical symptom, then, corresponds to a jutting over of this second state into the innervation of the body which is otherwise controlled by normal consciousness; a hysterical attack, on the other hand, is evidence that this second state is more highly organized, and, when the attack appears for the first time, it indicates a moment at which this hypnoid consciousness has taken hold of the subject’s entire existence, in other words, an acute hysteria; when, however, the attack is recurrent and contains a memory, it indicates a return of that moment. Charcot has already voiced the thought that hysterical attacks might be the rudiments of a condition seconde.”
Contents: Freud discusses Charcot’s studies on hysterical attacks. 1) the epileptoid phase, 2) the phase of large movements, 3) the (hallucinatory) phase of attitudes passionelles, 4) the concluding phase of delirium. Freud focuses on stage three attitudes passionelles distinguished by attitudes and gestures which belong to scenes of passionate movement, which the patient hallucinates and often accompanies with the corresponding words. He saw these as the person reliving the initial trauma.
My Observations: Today, female hysteria is no longer a recognised illness, but different manifestations of hysteria are recognised in other conditions such as schizophrenia, borderline personality disorder, conversion disorder, and anxiety attacks or psychogenic non-epileptic seizures. Whereas in Freud’s time, hysteria was researched extensively and (in the case of Charcot) even turned into a piece of theatre. People would come from far and wide to watch Charcot hypnotise his patients to reproduce hysterical attacks (likely what we would now call non-epileptic seizures) in front of their eyes.

In this chapter, we see what appears to me to be the first conceptualisation of what would go on to be coined by Jung as a Complex (historically, the term originated with the Neurologist and Psychiatrist Theodor Ziehen who described complexes as combinations of associated ideas. For more on this, see Introduction to Physiological Psychology by Theodor Ziehen).
5
Quote from the chapter: “Why the psychotherapeutic method expounded here has a curative effect should now be clear. The method removes the effectiveness of the idea that had not originally been abreacted by allowing its trapped affect to drain away through speech; it then submits the idea to associative correction by drawing it into normal consciousness (under light hypnosis) or by using the doctor’s suggestion to remove it, as occurs in somnambulism with amnesia.”
Contents: Freud concludes by stating the premise of the book. That they have unearthed causal elements connected to individuals hysteria which they will expound upon in this book.
II: Case Histories
1 Fräulein Anna O (Breuer)
/GettyImages-56466306-cropped-56a7976d5f9b58b7d0ebf6c5.jpg)
Anna O’s Story:
“In July 1880, when in the country, the patient’s father fell seriously ill of a sub-pleural abscess; Anna shared the nursing with her mother. She woke up one night in a state of great anxiety about the patient’s high fever and under the strain of expecting the arrival of a surgeon from Vienna for the operation. Her mother had gone away for a while and Anna was sitting at the patient’s bedside with her right arm resting over the back of the chair. She fell into a daydreaming state and saw a black snake coming from the wall towards the patient in order to bite him. (It is highly likely that there really were snakes in the field behind the house, that the girl had already been frightened by them before, and that they were now providing the material for the hallucination.) She wanted to fend off the creature, but was as if paralysed. Her right arm hanging over the back of the chair had ‘gone to sleep’, becoming anaesthetic and paretic, and when she looked at it, her fingers turned into tiny snakes with skulls (her nails). It seems likely that she tried to chase the snakes away with her paralysed right hand, and that through this the anaesthesia and paralysis became associated with the hallucination of the snake. When the snake had disappeared, she tried in her terror to pray, but every language failed her, she could speak none at all until finally she came upon a nursery rhyme in English and then found that she could also think and pray in this language. The spell was broken by the whistle of the train bringing the doctor whom they were expecting. When the next day she had gone to recover a hoop from a bush where it had been thrown during a game, a bent twig revived the snake-hallucination, and at once the arm that she had stretched out froze. This now happened repeatedly, whenever a more or less snake-like object provoked the hallucination.”
In this way, her illness began and got progressively worse. Breuer was able to cure her over time by allowing her to talk about her problems. See the below quote…
“The first time that – by chance and quite unprovoked – talking things through during the evening hypnosis caused a long-standing disturbance to disappear, I was very surprised. There had been a period of intense heat during the summer and the patient had suffered from a terrible thirst, for, although she could give no explanation for it, it had suddenly become impossible for her to drink. She would pick up the glass of water she was longing for, but as soon as it touched her lips she would push it away as if she were hydrophobic. At the same time it was clear that during these few seconds she was in an absence. She lived only on fruit, melons, etc., so as to ease her excruciating thirst. This had been going on for about six weeks, when, in her hypnosis, she grumbled about her English lady-companion, whom she did not like, and then, giving every sign of disgust, recounted how she had gone into her companion’s room and seen her small dog, the revolting animal, drinking out of a glass. She explained that she did not say anything, for fear of being impolite. Having given vent to the irritation that had been there inside her, she asked for a drink, drank a great quantity of water without any inhibition and woke from the hypnosis with the glass at her lips. At this the disturbance had disappeared forever. Other strange and stubborn quirks disappeared in the same way once the experience that had caused them had been recounted. But a great step forward was taken when the first of the long-term symptoms, the contracture of the right leg, disappeared (which was admittedly already much improved). On the basis of these experiences – namely that in this patient the hysterical phenomena disappeared as soon as the event that had caused the symptom was reproduced in hypnosis – a technical-therapeutic procedure was developed which left nothing to be desired in terms of logical consistency and systematic implementation. Each individual symptom in this complicated clinical picture was dealt with separately: all the occasions on which the symptom had appeared were narrated in reverse order, starting with the days before the patient was confined to bed and working backwards as far as the cause of its first appearance. Once this had been recounted, the symptom was permanently removed.”
My Observations: It is amazing to read about the beginning of the modern therapy we all take for granted. It all began here with a Doctor trying whatever he can to help his patient.
Refer to the book for the remaining four case studies.
2. Frau Emmy von N. (Freud)
3. Miss Lucy R. (Freud)
4. Katharina (Freud)
5. Fraulein Elisabeth von R.(Freud)
III: Theoretical Issues (Breuer)
In this chapter, Breuer goes into more detail about what was hinted at in the Preliminary Statement on the psychical mechanism behind hysteria.
1. Are all Hysterical Phenomena Ideogenie?
He starts by making it clear that not all Hysterical phenomena must arise first from an idea, although perhaps they do in more cases than we like to think.
2. Intracerebral Tonic Excitation – Affects
Here he introduces the concept of the brain as an electrical system in which nerves can have too much excitation, in which additional action (or reaction) is required to de-spell the energy when faced with traumatic events.
3. Hysterical Conversion
Hysterical conversion occurs when the energy of nerves becomes so great that a sort of “short-circuit” occurs. Causing the initial charge of energy to branch off from its initial trajectory and into an abnormal reaction. If this happens enough, a person may even forget why they even have this abnormal reaction. It is at this point that the hysterical “conversion” is complete.
This is why at first assessment, an individual’s abnormal reactions may appear to be purely somatic without any psychological roots.
Why is it that an abnormal reflex is created in the first place? Using the same analogy of the electrical system, Breuer explains that when we repress the reaction, it simply follows the ‘path of least resistance’.
My Observations: This reminds me of a recent study that demonstrated increased cortical connectivity resulting from a dose of Psilocybin.
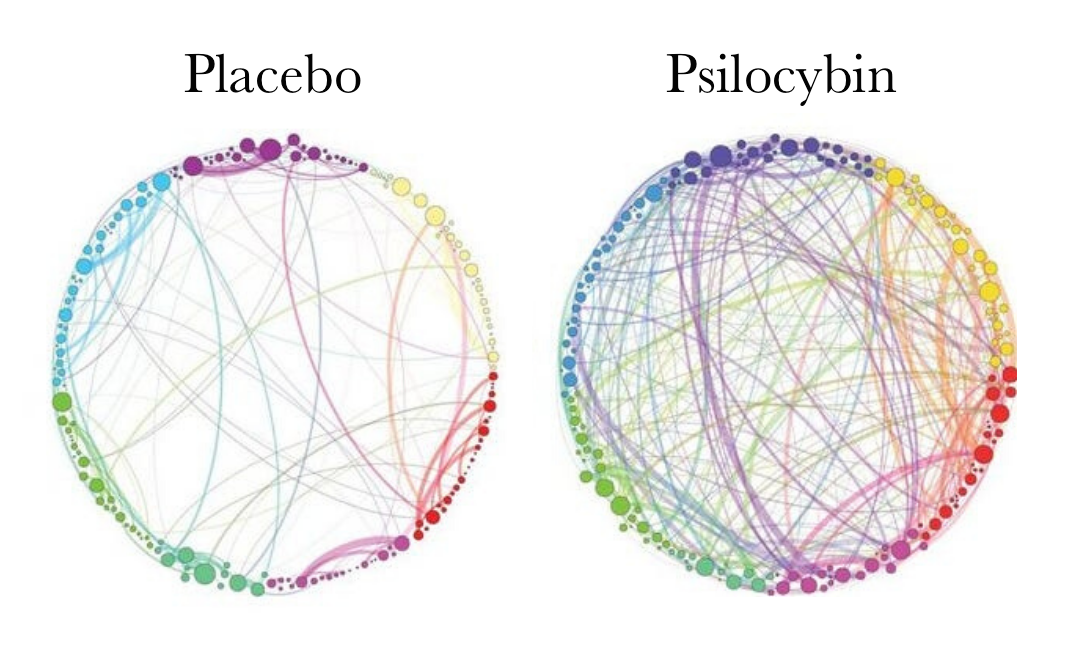
This increased connectivity could be why Psilocybin can help people with mental illness. Using Breuer’s analogy of the mind as an electrical system helps the “electricity flow” on the correct path again.
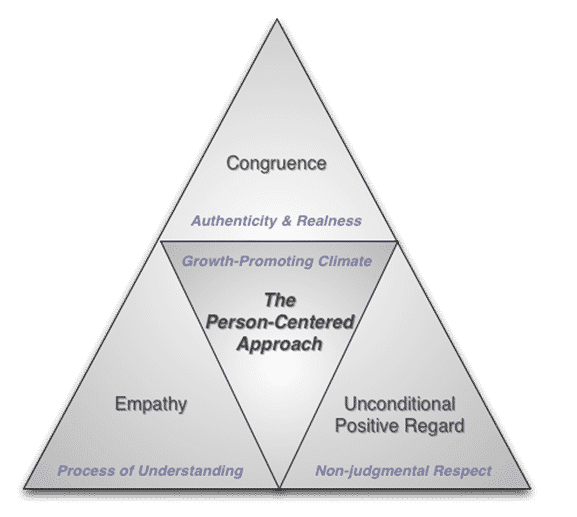
Carl Roger’s Person-Centered Approach emphasises how a strong therapeutic alliance facilitates a person’s growth by generating an authentic, non-judgmental space, which reduces avoidance or repression and allows the ‘flow of associations’ to occur. The electrical signal doesn’t hit resistance as the mind is allowed to associate its disparate components freely. An associated mind is a healthy mind.
On the flip side of the coin, having irreconcilable differences in beliefs also makes these sorts of repression more likely, such as navigating issues of sexuality and anger with a puritanical morality. As quoted earlier, “in hysteria groups of ideas originating in hypnoid states are present which are excluded from associative exchange with the other ideas, but which, as they can associate amongst themselves, represent the more or less highly organized rudiment of a second consciousness, a condition seconde.” Cognitive therapies will often focus on challenging irrational dogmatic beliefs that stop the flow of associations in a person’s psyche.
4. Hypnoid States
Breuer talks about how trance like states are often correlated with the development of hysterical conversion and that such states can mean a hysterical symptom bypasses the conscious mind when it is formed. Making it hard to identify the origin of a symptom outside of hypnosis.
“But if this is the case, if the recollection of the psychical trauma is to be regarded as an agent that, like a foreign body, exercises an effect in the present long after it has forced its way in and yet the patient has no consciousness of these recollections and their emergence, then we have to admit that unconscious ideas exist and are operative.”
5. Ideas that are Unconscious or Inadmissible to Consciousness, Splitting of the Psych
“Freud’s observations and analyses prove that the splitting of the psyche can also be caused by ‘defence’, that is, by the deliberate diverting of consciousness from distressing ideas.”
6. Innate Dispositions; The Development of Hysteria
“Nursing loved ones and being in love are the most common situations of this kind. Experience shows that nursing and strong sexual feelings also play the main role in most of the more closely analysed case histories of hysterics. I suspect that the habitual doubling of psychical capability or the doubling determined by affect-laden situations significantly predisposes to a genuine pathological splitting of the psyche. It turns into this when the two co-existing series of ideas cease to have the same kind of content, when one of them contains ideas that are inadmissible to consciousness, ideas that have been fended off or those that come from hypnoid states. The confluence of the two chronologically separated streams that occurs regularly in healthy people is then impossible and a split-off area of unconscious psychic activity is permanently established. This hysterical splitting of the psyche has the same relation to the healthy person’s ‘double self’ as do hypnoid states to normal daydreaming. The pathological quality in the latter is determined by amnesia, and in the former by the inadmissibility of the ideas to consciousness.”
III: On The Psychotherapy of Hysteria (Freud)
1
Quote from the chapter: “So, proceeding from Breuer’s method, I came to be occupied principally with the aetiology and mechanism of neuroses. I then had the good fortune of achieving some useful results in a relatively short period of time. What struck me initially was the recognition that in as much as one could speak of how the acquisition of neuroses is caused, the aetiology was to be sought in sexual factors.”
“I know no better means of working out a severe case of complicated neurosis in which there is a greater or lesser element of hysteria than subjecting it to Breuer’s method. The first thing that happens is that whatever is exhibiting the hysterical mechanism disappears. But this analysis also taught me how to interpret the remaining manifestations and how to trace their aetiology, thereby securing the grounds for deciding which of the therapeutic instruments for combating neuroses is appropriate to the case in question. If I think of how much my judgement of a case of neurosis differs before and after having made such an analysis, I am almost tempted to believe that this analysis is indispensable to our understanding of a neurotic illness. I have, in addition, taken to combining the application of cathartic psychotherapy with a rest-cure, which, if required, can be built up to the complete Weir-Mitchell feeding treatment.“
Contents: Here, Freud discusses the delineation of neurosis instead of grouping them all as hysteria. He then discusses the limitations of Breuer’s cathartic method in that it rarely addresses the root causes (Although he states that in the case of Anna O Freud states it happened to). Freud had much less luck with the cathartic method and instead, he applied it in conjunction with his own psychoanalytic approach that addressed the (often sexual) root cause of issues.
2-5
Throughout the rest of this chapter, Freud described his method of psychoanalysis: applying pressure to the forehead and asking participants to share what first comes to mind. In this way, he would explore the pathological neurosis again and again until the patient found a resolution. He described the different kinds of resistance one might face and how this should be expected as part of the process.
IV: Hysterical Phantasies and Their Relationship to Bisexuality
In this final chapter, Freud emphasises the impact of sexual phantasy and repression on the development of hysterical symptoms. He begins to touch on a person’s dualistic nature, which brings healing, which he describes as a form of bisexuality. I believe this is part of what Jung expounded on in his work on the anima/animus. He goes into more detail on the hermaphroditic nature of a person’s psyche and its subsequent impacts in his book 3 essays on the theory of sexuality. Click here to read my summary of that book.